갖고 있던 고유 락을 해제하고, 스레드를 잠들게 하는 wait와 잠들어 있던 스레드 중 임의로 하나를 골라 깨우는 notify는 synchronized 블록이나 메소드에서 호출되어야하고, 올바르게 사용하기 까다로우니 고수준 동시성 유틸리티를 사용하자. java.util.concurrent의 고수준 유틸리티는 세 범주로 나눌 수 있다. 그 중 하나는 아이템80에서 설명했던 실행자 프레임워크다. 이 외에 두 가지가 더 있다.
동시성 컬렉션(Concurrent Collection)
동시성 컬렉션은 List, Queue, Map 같은 표준 컬렉션 인터페이스에 동시성을 가미해 구현한 고성능 컬렉션으로, 높은 동시성에 도달하기 위해 동기화를 각자의 내부에서 수행한다. 따라서 동시성 컬렉션에서 동시성을 무력화하는 건 불가능하며, 외부에서 락을 추가로 사용하면 오히려 속도가 느려진다.
동시성 컬렉션에서 동시성을 무력화하지 못해 여러 메소드를 원자적으로 묶어 호출하는 일 역시 불가능하니, 여러 기본 동작을 하나의 원자적 동작으로 묶는 '상태 의존적 수정' 메소드들이 추가되었고, 이 메소드들은 자바 8에서는 일반 컬렉션 인터페이스에도 디폴트 메소드로 추가됐다.
Map 예시

putIfAbsent 메소드를 보면, 주어진 키에 매핑된 값이 아직 없을 때 새 값을 집어넣고 null 반환, 기존 값이 있다면 그 값을 반환한다.
이 메소드 덕에 안전한 정규화 맵(canonicalizing map)을 쉽게 구현할 수 있다. 예로 String.intern 메소드의 동작을 흉내내보자.
String의 intern 메소드를 간략하게 말하면, String pool에서 literal이 존재하는지 확인하고, 존재한다면 그 문자열을 반환, 존재하지 않는다면(new String("")을 통해 생성되어 literal에 존재하지 않는 경우) String pool에 문자열을 등록하고 그 문자열을 반환한다.
public class Intern {
private static final ConcurrentMap<String, String> map =
new ConcurrentHashMap<>();
public static String intern(String s) {
String previousValue = map.putIfAbsent(s, s);
return previousValue == null ? s : previousValue;
}
}
이 메소드는 최적의 방법이 아니다. ConcurrentHashMap은 동시성을 보장하니 내부적으로 synchronized 키워드를 사용한다. 하지만 get 같은 검색 기능에는 동기화를 사용하지 않도록 최적화되어 있다. get 메소드를 보면 어디에도 동기화를 하지 않는다는 것을 알 수 있다.
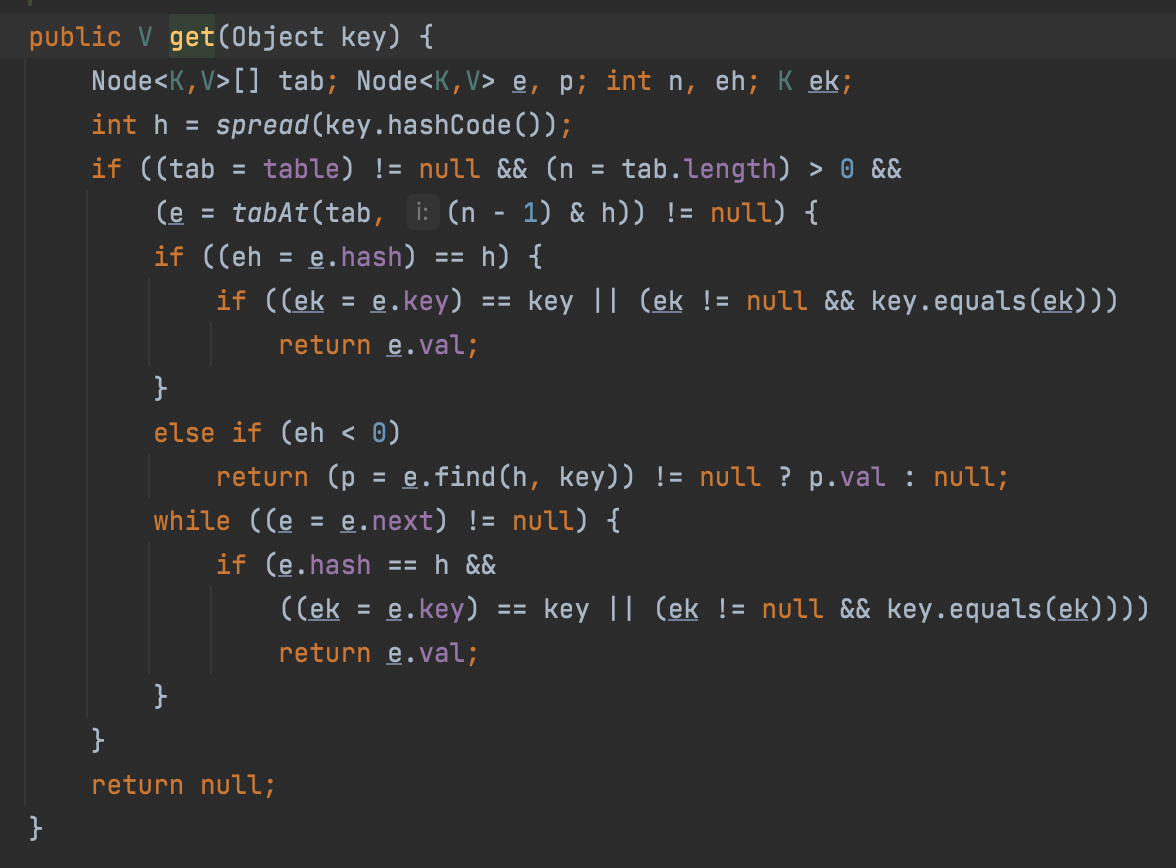
ConcurrentHashMap에서 값을 추가하거나 수정하는 작업에서만 synchronized 키워드를 사용하고, 심지어 블록으로 사용한다.
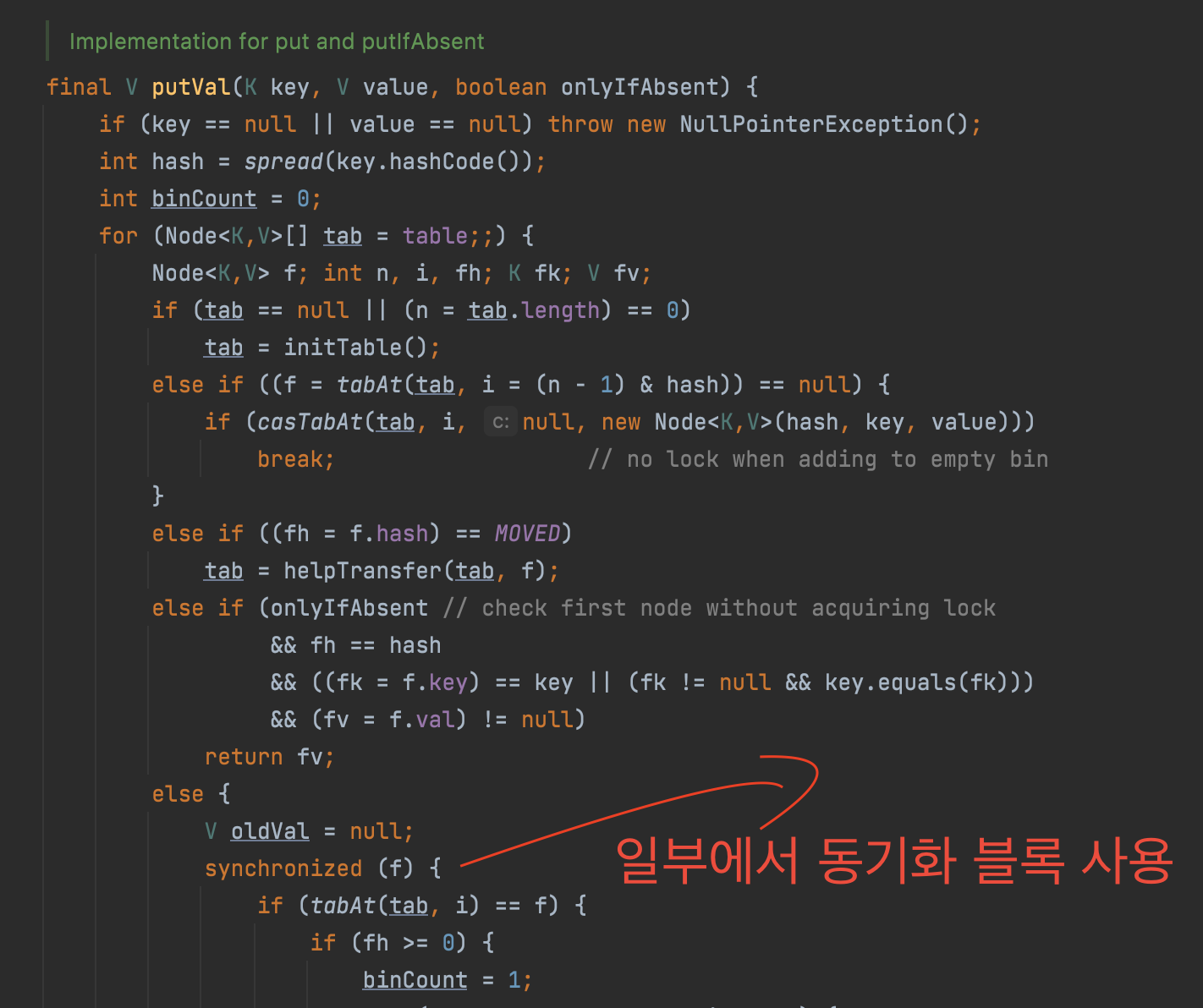
즉, 값을 검색하는 기능에서는 동기화를 하지 않고 값을 수정하거나 추가할 때도 일부에서만 동기화 블록을 사용하도록 최적화 되었음을 알 수 있다. 그렇다면 위 Intern 예제는 어떤식으로 만들어낼 수 있을까?
public static String intern(String s) {
String result = map.get(s);
if (result == null) {
result = map.putIfAbsent(s, s);
if (result == null)
result = s;
}
return result;
}
수정된 코드는 다음과 같다. get을 먼저 호출해 필요할 때만 putIfabsent를 호출하면 값이 존재하는 경우 더 빠르게 동작할 수 있다.
그런데, map.get을 했음에도 존재하지 않을 경우 mapIfAbsent 메소드를 호출했음을 알 수 있다. Map 인터페이스의 경우 동일한 상황에서 put을 했음에도 불구하고 말이다. 당연히 동시성 문제를 생각해야한다. map.get 메소드를 호출하고 존재하지 않을 경우 다시 put을 하려고 동기화 블록에 들어가기 전에 다른 스레드가 put을 해버릴 수도 있으니 다시 확인이 필요하다.
따라서 map에 value가 존재하면 반환하고, 존재하지 않으면 putIfAbsent를 이용해 저장한다. 이 때 다른 스레드가 값을 추가했다면 result에 그 값이 담길 것이다. result가 null인지 다시 확인하며 실제로 추가됐는지 확인할 수 있고, 정상적으로 저장되었다면 s의 값을 result에 담으면 된다. 그 후 반환하는 것이다.
ConcurrentHashMap은 동시성이 뛰어나고 속도도 무척 빠르다. 위에 만든 메소드는 String.intern보다 몇 배는 빠르지만 어디까지나 String.intern 메소드는 오래 실행되는 프로그램에서 메모리 누수를 방지하는 기술이 들어간 것을 감안하자.
이전엔 동시성 컬렉션 대신 Collections.synchronizedMap, 동기화 컬렉션을 이용했고 당연하게도 Collections.synchronizedMap보다 ConcurrentHashMap을 사용하는 것이 훨씬 좋다. 동기화된 맵을 동시성 맵으로 교체하는 것만으로 동시성 애플리케이션의 성능은 극적으로 개선된다. 아니 그만큼 차이난다고? 라고 생각되었지만 위에서 간단하게 알아본 ConcurrentHashMap의 put과정과 get 과정을 생각하며 Collections.synchronizedMap의 내부 메소드들을 보자.

모든 메소드들을 뮤텍스 필드를 동기화 걸어서 사용함을 알 수 있다. 그리고 동기화 블록을 걸어서 사용하는 것은 자신이 가진 Map 구현체의 메소드들을 호출하는 것이다. 그에 반해 ConcurrentHashMap은 get 같은 검색 기능에서 동기화를 사용하지 않고 값을 수정하거나 추가하는 과정에서도 일부 코드블록에 한해 동기화 블록을 사용한다. 오늘도 라이브러리들에게 정말 감사합니다 🙏🏻🙏🏻🙏🏻
Queue 예시
컬렉션 인터페이스 중 일부는 작업이 성공적으로 완료될 때까지 기다리도록 확장되었다. Queue를 확장한 BlockingQueue 인터페이스에 추가된 메소드 중 take는 큐의 첫 원소를 꺼낸다. 이 때 만약 큐가 비었다면 새로운 원소가 추가될 때까지 기다린다. 이런 특성 덕에 작업 큐(생산자-소비자 큐)로 쓰기에 적합하다.
작업 큐는 하나 이상의 생산자(producer) 스레드가 작업(work)를 큐에 추가하고, 하나 이상의 소비자(consumer) 스레드가 큐에 있는 작업을 꺼내 처리하는 형태다. 아이템 80에서 봤던 ThreadPoolExecutor를 포함한 대부분의 실행자 서비스 구현체에서 BlockingQueue를 사용한다.
간단하다. BlocingQueue의 구현체에서 아무 작업이 없을 때 take 메소드를 호출하고, 다른 스레드에서 BlockingQueue에 어떠한 작업도 offer나 add하지 않는다면 그 스레드는 종료되지 않는다.
동기화 장치(synchronizer)
동기화 장치는 스레드가 다른 스레드를 기다릴 수 있게 하여 서로 작업을 조율할 수 있게 해준다.
ex) CountDownLatch, Semaphore, CyclicBarrier, Exchanger, Phaser
이 중에서 CountDownLatch에 대해서 알아보자. 나머지 동기화 장치들은 자바봄에서 봤던 레퍼런스를 참고했다😀
CountDownLatch는 하나 이상의 스레드가 또 다른 하나 이상의 스레드 작업이 끝날 때까지 기다리게 한다.

유일한 생성자는 int 값을 받으며 이 값이 Latch의 countDown 메소드를 몇 번 호출해야 대기중인 스레드들을 꺠우는지를 결정한다.
예를 들어 어떤 동작들을 동시에 시작해 모두 완료하기까지 시간을 재는 간단한 프레임워크를 구축한다고 해보자.
/**
*
* @param executor 동작들을 실행할 실행자
* @param concurrency 동작을 몇 개나 동시에 수행할 수 있는지인 동시성 수준
* @param action 진행할 동작 Runnable
* @return 동작들이 모두 완료하기까지 걸린 시간
* @throws InterruptedException
*/
public static long time(Executor executor, int concurrency,
Runnable action) throws InterruptedException {
// 모든 스레드가 동작 준비가 완료되는 순간을 위한 래치
CountDownLatch ready = new CountDownLatch(concurrency);
// 모든 스레드가 동작 준비가 완료되고 작업을 들어가게 하기 위한 래치
CountDownLatch start = new CountDownLatch(1);
// 모든 스레드가 동작을 완료한 순간을 위한 래치
CountDownLatch done = new CountDownLatch(concurrency);
for (int i = 0; i < concurrency; i++) {
executor.execute(() -> {
// 타이머에게 준비를 마쳤음을 알린다.
ready.countDown();
try {
// 메인 스레드에서 start하게 하기를 기다린다.
start.await();
action.run();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
// 작업이 종료되면 countdown한다.
done.countDown();
}
});
}
//concurrency 만큼 countDown이 완료될 때까지 기다린다. 즉, 모든 스레드가 준비될 때까지 대기
ready.await();
long startNanos = System.nanoTime();
// 모든 스레드가 action을 동시에 실행할 수 있도록 카운트를 0으로 만든다.
start.countDown();
// 모든 작업이 종료될 떄까지 대기한다.
done.await();
// 소요시간을 반환
return System.nanoTime() - startNanos;
}
이상의 기능을 wait와 notify만으로 구현한다면 난해하고 지저분한 코드가 되지만, CountDownLatch를 쓰면 직관적으로 구현할 수 있다.
여기서 주의할 점이 있는데, time 메소드에 넘겨진 executor는 concurrency 매개변수로 지정한 동시성 수준만큼 스레드를 생성할 수 있어야한다. 그렇지 못하면 이 메소드는 결코 끝나지 않는다.
ready CountDownLatch는 concurrency만큼 countdown이 되야 메인 스레드에서 시간을 측정할 수 있고, 다른 스레드들에서는 ready가 await가 끝나고 startNanos를 기록 후 start가 countdown이 될 때까지 await하고 있다. executor가 concurrency만큼 스레드를 생성할 수 없다면 countdown이 진행되지 못하니 이 메소드가 끝날 수 없는 것이다.
이런 상태를 스레드 기아 교착상태(thread starvation deadlock)라 한다. 여러 프로세스가 동일 자원 점유를 요청하며, 여러 프로세스가 부족한 자원을 점유하기 위해 경쟁을 해서, 특정 프로세스는 영원히 자원 할당이 되지 않는 것이다. 따라서 따로 예외 처리를 해줘야한다.
그리고 InterruptedException을 캐치하면 작업자 스레드는 interrupt() 메소드를 호출해서 인터럽트를 되살리고 자신은 run 메소드에서 빠져나옴을 알 수 있다. 이렇게 해야 실행자가 인터럽트를 적절하게 처리할 수 있다.
+) 시간 간격을 잴 때는 System.currentTimeMillis가 아닌 System.nanoTime을 사용하자.
더 정확하고 정밀하며 시스템의 실시간 시계의 시간 보정에 영향 받지 않는다. 그리고 위 예제 코드는 작업에 충분한 시간(ex 1초 이상)이 걸리지 않으면 정확한 시간 측정이 어려움으로 해야한다면 jmh 같은 특수 프레임 워크를 사용하자.
wait와 notify를 사용해야할 때
동시성 유틸리티를 사용하는게 옳지만, 어쩔 수 없이 레거시 코드를 다뤄야할 때도 있다.
wait 메소드는 스레드가 어떤 조건이 충족되기를 기다리게 할 때 사용하고 락 객체의 wait 메소드는 반드시 그 객체를 잠근 동기화 영역 안에서 호출해야한다. 표준적인 방법은 다음과 같다.
synchronized (obj) {
while (<조건 미충족>) {
obj.wait(); // 락을 놓고, 깨어나면 다시 잡기
}
... // 조건 충족시 동작 수행
}
wait 메소드를 사용할 땐 반드시 대기 반복문(wait loop) 관용구를 사용하고 반복문 밖에서는 절대 호출하지 말자.
반복문은 wait 호출 전후로 조건이 만족하는지 검사하는 역할을 한다.
대기 전 조건을 검사해 조건이 이미 충족되었다면 wait을 건너뛰게 하는 것은 응답 불가 상태를 예방하는 조치다.
만약 조건이 충족되었는데 다른 스레드가 notify 혹은 notifyAll 메소드를 먼저 호출한 후 대기 상태로 빠지면 그 스레드는 다시 깨울 수 있다고 보장할 수 없다.
대기 후에 조건을 검사해 조건이 충족되지 않았다면 다시 대기하는 것은 안전 실패를 막는 조치다.
만약 조건이 충족되지 않았는데 스레드가 동작을 이어가면 락이 보호하는 불변식을 깰 위험이 있다. 조건이 만족되지 않아도 스레드가 깨어날 수 있는 상황의 예시를 살펴보자
- 스레드가 notify를 호출한 다음 대기 중이던 스레드가 깨어나는 사이! 다른 스레드가 락을 얻어 동기화 블럭 안의 상태를 변화시킬 수 있다: [예시참조]
- 조건이 만족되지 않았는데 다른 스레드가 실수 혹은 악의적으로 notify를 호출할 수 있다. 공개된 객체를 락으로 사용해 대기하는 클래스는 이런 위험에 노출되고, 외부에 노출된 객체의 동기화된 메소드 안에서 호출하는 wait는 모두 이 문제에 영향을 받는다.
- 깨우는 스레드의 관대함에, 대기 중인 스레드 중 일부만 조건이 충족되도 notifyAll을 호출해 모든 스레드를 깨울 수 있다.
- 대기중인 스레드가 notify 없이 깨어날 수 있는데 허위 각성(spurious wakeup) 현상이다.
notify vs notifyAll
notify는 스레드 하나만 깨우며, notifyAll은 모든 스레드를 깨운다. 일반적으론 언제나 notifyAll을 사용하는게 낫다. 깨어나야 하는 모든 스레드가 깨어남을 보장하니 항상 정확한 결과를 얻을 수 있을 것이고, 다른 스레드까지 깨어날 수도 있긴 하지만 정확성에는 영향을 주지 않는다. 위에서 했던 것처럼 기다리던 조건이 충족되었는지 확인해 충족되지 않았다면 다시 대기할테니 말이다.
모든 스레드가 같은 조건을 기다리고, 조건이 한 번 충족될 때마다 단 하나의 스레드만 헤택을 받는다면 notify를 사용해 최적화할 수도 있지만 외부로 공개된 객체에 대해 실수 혹은 악의적으로 notify를 호출하는 상황 대비를 위해 wait를 반복문 안에서 호출했듯, notifyAll을 사용하면 관련없는 스레드에서 실수 혹은 악의적으로 wait를 호출하는 공격으로부터 보호할 수 있다. 그런 스레드가 notify를 삼키면 꼭 깨야할 스레드가 영원히 대기할 수도 있다.
정리
코드를 새로 작성한다면 wait, notify를 쓸 이유가 거의 없으니 고수준 유틸리티를 사용하고, 레거시 코드라면 wait는 반복문에서 호출하자.
notify보다 notifyAll을 사용하자. notify를 사용해야 한다면 응답 불가 상태에 빠지지 않게 주의하자
** 이펙티브 자바 외 출처 **
https://www.baeldung.com/java-concurrent-map
* 위 글은 EffectiveJava 3/E 책 내용을 정리한 글로, 저작권 관련 문제가 있다면 댓글로 남겨주시면 즉각 삭제조치 하겠습니다.
'Reading > Effective Java' 카테고리의 다른 글
| [Effective-Java] Item 83. 지연 초기화는 신중히 사용하라 (0) | 2022.01.05 |
|---|---|
| [Effective-Java] Item 82. 스레드 안전성 수준을 문서화하라 (0) | 2022.01.05 |
| [Effective-Java] Item 80. 스레드보다는 실행자, 태스크, 스트림을 애용하라 (0) | 2022.01.05 |
| [Effective-Java] Item 79. 과도한 동기화는 피하라 (1) | 2022.01.05 |
| [Effective-Java] Item 78. 공유 중인 가변 데이터는 동기화해 사용하라 (0) | 2021.12.30 |



